Meet the Presenters
This article is based on a webinar presented by STLE Education on January 17, 2024. Machine Learning and Artificial Intelligence in Tribology is available at www.stle.org: $39 for STLE members, $59 for all others.
STLE member Dr. Prathima Nalam is an associate professor in the Department of Materials Design and Innovation at the University at Buffalo, State University of New York. Her research focuses on advancing alternative materials that will leave a low-carbon footprint on the environment. Her research interests lie in developing next-generation materials in the fields of tribology, filtration and bioengineering. She is a member of the Editorial Board for Tribology Letters (Springer-Nature) and associate editor for Journal of Tribology. Dr. Nalam is the recipient of the Swiss National Science Foundation Fellowship and the STLE Early Career Award. In 2023, she received a National Science Foundation CAREER Award in support of her work to understand the behavior of liquids in two-dimensional confined spaces for generating lubricious surfaces. You can reach her at prathima@buffalo.edu.

Dr. Prathima Nalam
STLE member Dr. Nick Garabedian is currently the CEO of datin—a newly-founded software startup pursuing scientific superintelligence built on research data management and sharing. Before establishing datin, he was an Alexander von Humboldt postdoc fellow and research group leader at the Karlsruhe Institute of Technology (KIT) in Karlsruhe, Germany. His research interests lie at the intersection of AI, research data management and FAIR data. The goal of his research activities and his pivot from academia into entrepreneurship is to create an AI partner for every scientist in the world by engineering a new protocol for research knowledge and data. You can reach him at nick@datin.io.

Dr. Nick Garabedian
STLE member Max Marian is professor and executive director of the Institute of Machine Design and Tribology (IMKT) of Leibniz University Hannover, Germany, and assistant professor for multiscale engineering mechanics at the Department of Mechanical and Metallurgical Engineering of Pontificia Universidad Católica de Chile. His research focuses on energy efficiency and sustainability through tribology, with an emphasis on the modification of surfaces through micro-texturing and coatings (diamond-like carbon and 2D materials). Besides machine elements and engine components, he expanded his fields toward biotribology and artificial joints as well as triboelectric nanogenerators. His research is particularly related to the development of numerical multiscale tribo-simulation and machine learning approaches. He has published more than 70 peer-reviewed publications in reputable journals, given numerous conference and invited talks and has been awarded with various individual distinctions as well as best paper and presentation awards. Furthermore, he was listed among the Emerging Leaders 2023 of Surface Topography: Metrology and Properties. Moreover, he is on the editorial boards of Frontiers in Chemistry Nanoscience, Industrial Lubrication and Tribology, Lubricants as well as Tribology - Materials, Surfaces & Interfaces. You can reach him at marian@imkt.uni-hannover.de.

Max Marian
KEY CONCEPTS
•
AI is the field of developing computers and robots that are capable of behaving in ways that both mimic and go beyond human capabilities.
•
The only truly bad data for AI/ML purposes in science are data that have not been appropriately annotated; in other words, the conditions of the experiment are unknown or unclear. Data should meet the principles of findability, accessibility, interoperability and reusability (FAIR).
•
ML and AI present an exciting opportunity for tribology to tackle long-standing challenges.
Machine learning (ML) and artificial intelligence (AI) are attracting more interest and research while offering an exciting opportunity to tackle long-standing challenges in the tribology field. This article presents some of the different categories of ML algorithms and the types of problems they were designed to address, as well as example tribological problems that can be solved with the help of ML. Access to high quality data is a fundamental requirement for developing any ML model. Database concepts that are particularly well suited for a diverse field like tribology are explored. The presenters have studied and presented on this topic through a number of published articles, symposia and meetings.
This article is based on an STLE webinar titled Machine Learning and Artificial Intelligence in Tribology. Prathima Nalam presents a general introduction to the topic. Nick Garabedian discusses data curation and analysis, and Max Marian presents ML applications to experimental and numerical data. See Meet the Presenter for more information.
Defining AI and ML
Nalam notes that AI and ML are often used as interchangeable terms but are actually different things. AI “is the field of developing computers and robots that are capable of behaving in ways that both mimic and go beyond human capabilities.” Nalam notes that “AI-enabled programs can analyze and contextualize data to provide information or automatically trigger actions without or with minimum human interference.”
In contrast, Nalam defines ML as a pathway to AI. ML “is a subcategory of AI that uses algorithms to automatically learn insights and recognize patterns from data, applying that learning to make increasingly better decisions.” ML is about developing intelligence from data through detecting and extrapolating patterns by employing advanced statistics.
ML includes several categories of learning, including deep learning, computer vision and natural language processing. In contrast with AI, which uses a human interface to proceed, deep learning employs huge networks of data in neural networks (similar to human brains) to generate multiple layers of processing to extract progressively higher-level features from the data. Deep learning is identified by having a much larger data set
without the human interface and by unsupervised learning with multiple layers of information processing, coupled with image recognition, sound recognition and hidden patterns. Computer vision involves processing visual information (e.g., graph extraction, image or plot extraction). Natural language processing is a way to communicate with machines. For example, machine learning uses online research coupled with documentation analysis to lead to predictive text. Human-robot collaborative interactions can create autonomous systems interfaced with AI/ML.
Why do AI/ML methods benefit tribology?
Optimizing tribological properties is a multi-parameter problem. For example, to learn experimental response as a function of temperature and concentration, you could assume 20 settings (i.e., levels) for both variables (i.e., factors). This translates to 400 separate experiments, which is challenging and time-consuming to perform. Alternatively, using a Bayesian Optimization Loop
(see Figure 1), prior knowledge and initial data are used to train the surrogate model, evaluate the acquisition function and use this information to select the next experiment(s).
1 This process is repeated until convergence is achieved, or the budget limit. This approach reduces the number of physical experiments that are needed.
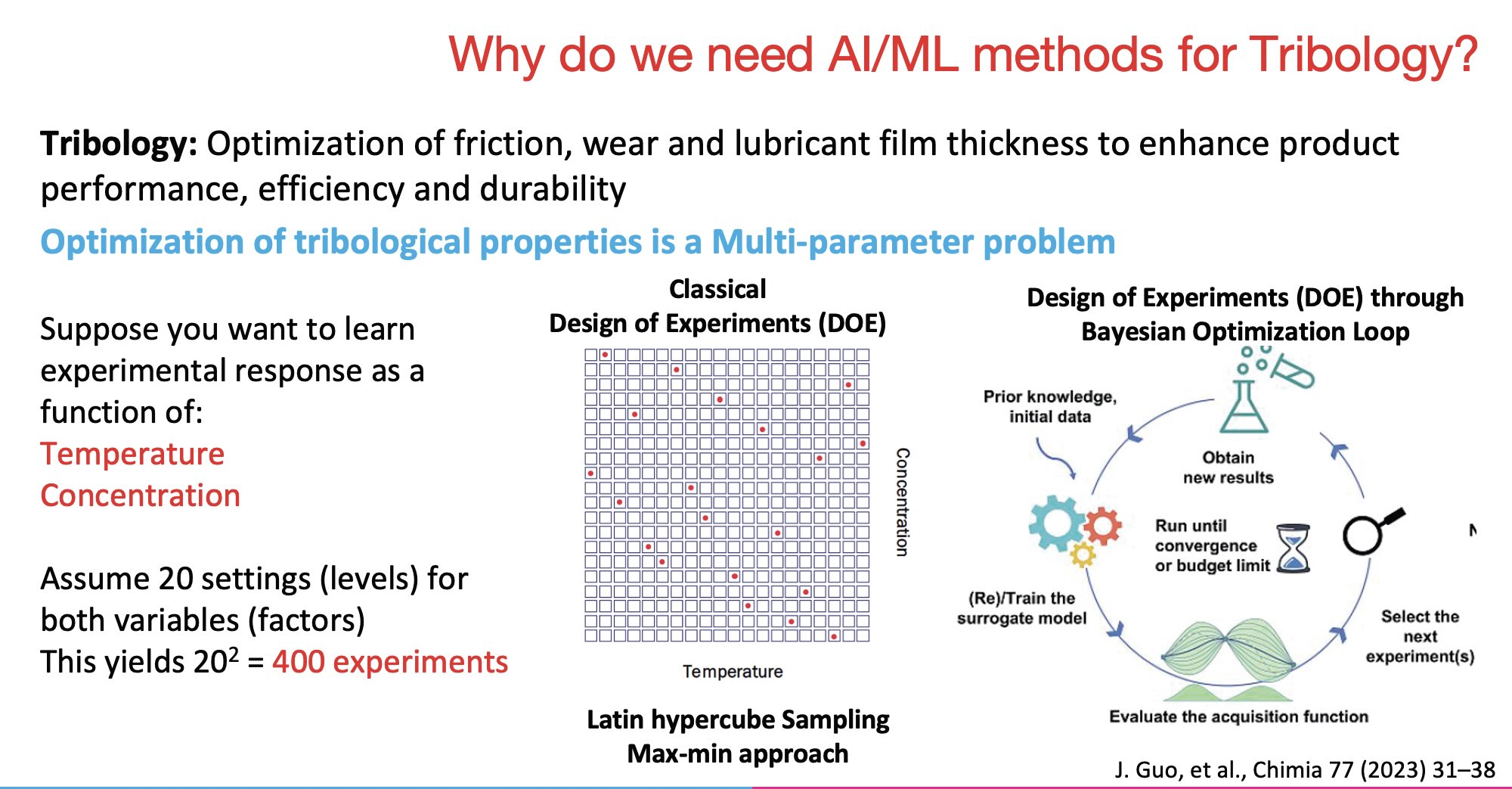 Figure 1. Design of experiments (DOE) through Bayesian Optimization Loop.1
Figure 1. Design of experiments (DOE) through Bayesian Optimization Loop.1
Tribological data is complex and spatiotemporal. Tribological properties (e.g., friction, wear, tribocorrosion, additive performance, etc.) present both spatial and temporal variations. The real-time generation of predictive models can deliver significant insights and solutions for enhancing the efficiency, dependability and longevity of mechanical systems across various industrial applications.
ML can allow for the generation of new physics. There is a need for new and better materials as well as for physics-based designs that enhance the performance of tribological components of mechanical systems.
2 Employing AI/ML allows for the access of vast amounts of tribological data (e.g., experimental measurements, simulations, historical records) to identify unexplored trends. AI/ML allow for the generation of hypotheses and estimations of their uncertainty. This process allows for accelerated scientific discovery by permitting the recognition of patterns and the development of critical correlations among parameters from the generated data.
Using these data-enabled tribological methods for industry will optimize tribological designs for enhanced system performance and reliability. These methods will also enable the capture of intricate interactions, dependencies and trends, while reducing experimental costs. It can also facilitate the prediction of system behavior, all of which empowers engineers to make well-informed decisions. These methods also enable digital transformations and develop advanced analytics, while providing customized solutions for industrial innovations in an accelerated approach.
Data
For ML to produce universally useful results, it needs to have access to all types of tribological data from both academic and industrial sources. The data can be both experimental or can come from thermodynamic and mathematical models. These data can include fundamental research data on material structure and composition, testing conditions and multiscale measurements of tribological properties. Real life test conditions, product design and manufacturing, and durability and efficiency can also be input. The only truly bad data for AI/ML purposes are data that have not been appropriately annotated; in other words, the conditions of the experiment are unknown or unclear. Data should meet the principles of findability, accessibility, interoperability, and reusability (FAIR).
Currently, multidisciplinary fields like tribology and material science operate in small-data regimes. When data are limited, Nalam notes the need to be economical with the limited data available by developing new and advanced algorithms that are suitable for small and sparse data and include strategies such as active learning and transfer learning. Strategies for acquiring new data include effective data management of processes of data collection, storage, screening, labeling, annotation, augmentation and other processes. Also, it is important for researchers to be resourceful by incorporating data and knowledge from different sources and fields. This can be accomplished by combining experiments and calculations, active learning and databases. Using available physics-based principles to make reasonable judgements while inter/extrapolating data, defining uncertainties and other techniques can also expand available data sets.
Nalam explains that data informatics is the study that covers the acquisition, storage, security integration, distribution and management of data along with processing it to obtain useful information and trends. Data management, data mining and cyber infrastructure are all ways to generate informatics. This is the right time to accelerate the use of AI/ML in tribology.
Data curation
Garabedian speaks on the importance of data and data curation to AI and how AI and ML allow for tackling grand tribological challenges. Obvious data problems are related to data quality, which is not the fault of the people collecting the data, but of a lack of awareness of ML needs. There is a narrow focus in data sources on their specific problem, making their data unusable for larger problems when it lacks appropriate annotation. This circles back to the goal of making all data meet FAIR standards.
FAIR data can be connected to other projects relatively easily and is ML ready by default, which avoids wasting scientific resources. FAIR data is not necessarily open data, which is data available for any purpose that is openly accessible, exploitable, editable and shareable by anyone. Ideally, open data should be FAIR data.
For tribology, FAIR data is not about just the one experiment, but about the entire chain of actions that generate the surface used in the experiment. In reality, the one experiment only occurs at the end of an entire chain of steps. To fully understand the data, the entire process needs to be digitalized.
Crowd-based involvement in data collection allows going up in scale, creating both a challenge and opportunity for tribology. Garabedian reports that in 2022, 92% of European businesses in research and development (R&D) entered the AI era still lacking the data needed to train or use ML models.
3 There is little indication that trend has since changed. Data quality is a gateway to effectively using ML and AI to solve big problems.
Usually, the community of large data recognizes 4 qualities: volume, variety, velocity and veracity. However, Garabedian would change the four qualities to:
•
Volume, which is not about gigabytes, but volume that is tailored to the acquisition rate relevant to the tribological phenomena.
•
Variety, which is about showing multiple perspectives, as well as about information on place and the temporal and spatial scales applicable to the experiment or simulation.
•
Connectivity, where every object mentioned has to be presented in the full context of the situation.
•
Completeness, where researchers provide computers with everything known about the problem in order to teach the computer.
Tribological data is extremely multifaceted. For example, data types can include topography, microstructure, friction force, sliding velocity, oxidation, wear, normal load and contact pressure, all with possible unknown confounding factors. To evaluate data sharing, Garabedian and his colleagues looked at five recent issues of seven tribology journals for their data sharing practices. Only a small amount of the data presented in these journals could be considered open access data. As a community, tribologists need to be willing to share their data while meeting FAIR standards.
One way to change the entire motivation behind data sharing is to use software that makes R&D easier and fosters collaboration. Using a tablet instead of a paper notebook is one approach. Direct uploading or automatic capture of experiments and analyses can result in findability to review and evaluate what is out there. There needs to be a quick and easy way to share data through public repositories like Zenodo, which is a European open research repository. Aggregating all these data can result in solutions to tribological problems.
Good data requires accounting for many dimensions simultaneously, including tracing objects, events, projects, time, data and metadata, all of which come into a data model that organizes these terms. The goal is for the entire effort to be wrapped into an AI observation to contain all the information. This will permit the extension of our definitions of the world.
ML applications
Marian spoke on ML applications for experimental and numerical data. In other words, he spoke to what can be perceivable with ML. Figure 2 shows algorithms that can be tailored to specific problems. ML can be focused on supervised learning, unsupervised learning and reinforcement learning. With supervised learning, predictive models can be used based on input and output data. With unsupervised learning, meaningful patterns can be identified only within the dataset from the input data.
4
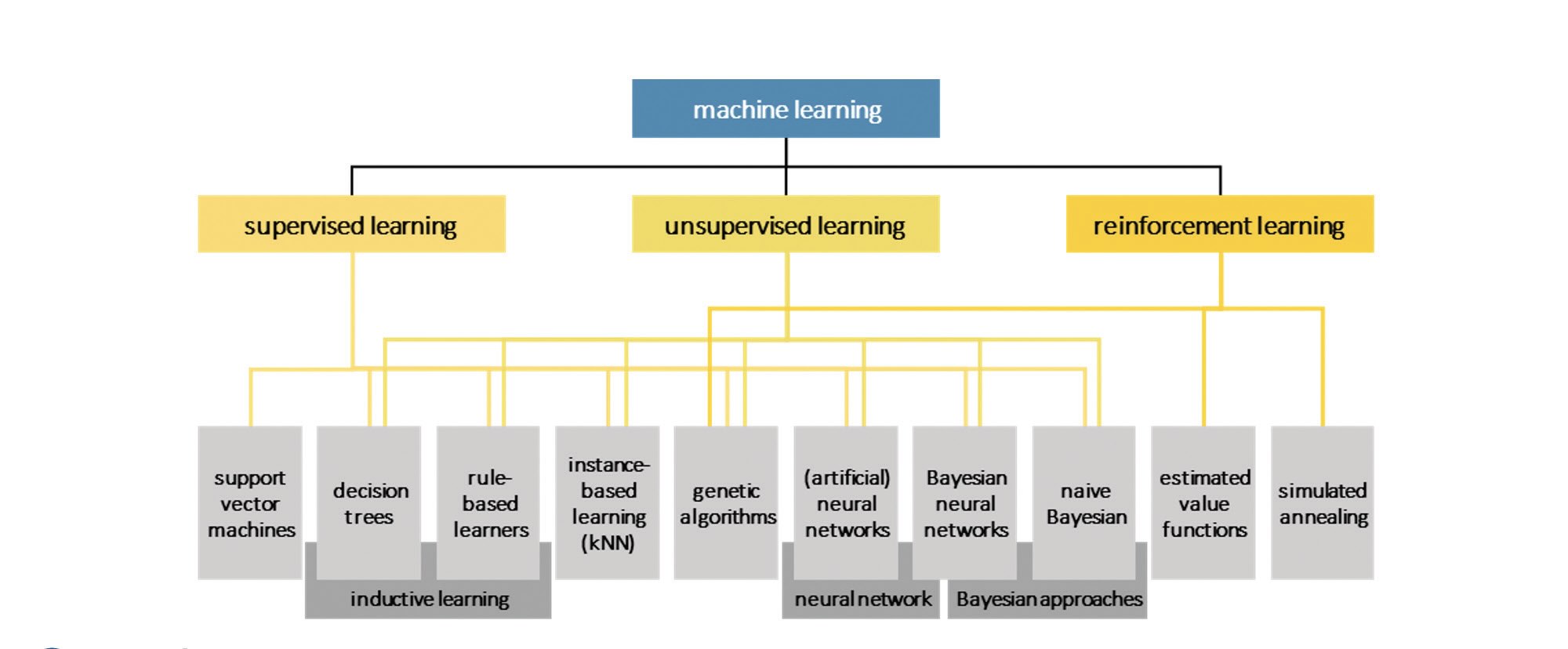 Figure 2. ML applications to experimental and numerical data. Adapted from Marian, M., & Tremmel, S. (2021), "Current trends and applications of machine learning in tribology—A review," Lubricants, 9 (9), 86, https://doi.org/10.3390/lubricants9090086
Figure 2. ML applications to experimental and numerical data. Adapted from Marian, M., & Tremmel, S. (2021), "Current trends and applications of machine learning in tribology—A review," Lubricants, 9 (9), 86, https://doi.org/10.3390/lubricants9090086
ML has many applications for experimental research. Since the 1990s, more and more studies have been published on these topics. Currently, ML is being directed mostly toward predicting the behavior of tribological systems, toward designing new systems and optimizing new systems or for the monitoring or controlling of tribological systems. Most of the data used is experimental data, emphasizing the need for FAIR data.
The most famous ML algorithms are trying to mimic the brain’s neural network to find relationships between input and output. The quality of a prediction will largely depend on the architecture of the neural network. The network can’t simply be a matter of plug-and-play algorithms. Instead, the best network is needed to yield the most accurate prediction.
Marian notes that it is hard or even impossible to find a single ML model that works best. The idea or philosophy behind ensemble ML is to train many models and combine them by averaging or voting.
Examples are convolutional neural networks (CNNs) that are used for the classification of wear particles in an internal combustion engine (ICE) lubricant. By providing images of different wear particles to the models, a prediction of the wear impacts was developed. Combining models improved the predictive accuracy dramatically.
5
A similar process was employed for the fault diagnosis of a tribo-mechanical clutch system by multi-feature extraction ensemble voting methods. Extracted vibration data, feature extraction, feature selection and a classification layer were used to train different kinds of ML algorithms individually. The algorithms were then combined into a voting process, which yielded superior training accuracy, validation accuracy and testing accuracy in prediction methods. Marian notes that there is no one single ML algorithm that will solve all problems, but by combining different algorithms, better results can be achieved. Using ML algorithms can speed up the design process by analyzing new data quickly without the need to perform new dynamic simulations.
6
Summary
ML and AI present an exciting opportunity for tribology to tackle long-standing challenges. There are several available ML and AI algorithms ready to be employed—a computational engineer or data scientist is not needed to try this approach. A fundamental requirement for developing any ML model is access to high quality data and, therefore, the establishment of FAIR data standards. There are already several successful case studies on ML and AI in the field of tribology and lubrication engineering. Even more remains to be explored.
Digitalization has to penetrate each process as much as possible to accelerate the process. FAIR data is a good way to do digitalization as it can lead to huge savings in terms of cost and time to market. Getting people to use the system is the greatest challenge, but when the solutions make the life of the user easier, this can be an easy sell. Any FAIR system will not contain more knowledge than the people in the lab.
REFERENCES
1. Guo, J., Ranković, B. and Schwaller, P. (2023), "Bayesian optimization for chemical reactions," Chimia, 77 (1-2), 31–38, https://doi.org/10.2533/chimia.2023.31
2. Sattari Baboukani, B., Ye, Z., G. Reyes, K., et al. (2020), "Prediction of nanoscale friction for two-dimensional materials using a machine learning approach," Tribology Letters, 68, 57, https://doi.org/10.1007/s11249-020-01294-w
3.
StageZero Technologies, 2022.
www.aitimejournal.com/ai-adoption-in-europe-2022-how-high-performers-generate-value/42593/
4.
Tremmel, S. and Marian, M. (2022), “Machine learning in tribology—More than buzzwords?”
Lubricants, 10 (4), 68,
https://doi.org/10.3390/lubricants10040068
5.
Shah, R., Sridharan, N. V., Mahanta, T. K., Muniyappa, A., Vaithiyanathan, S., Ramteke, S. M. and Marian, M. (2023), “Ensemble deep learning for wear particle image analysis,”
Lubricants, 11 (11), 461,
https://doi.org/10.3390/lubricants11110461
6.
Shandhoosh, V., Venkatesh S., N., Chakrapani, G., Sugumaran ,V., Ramteke M., S. and Marian, M. (2024), “Intelligent fault diagnosis for tribo-mechanical systems by machine learning: Multi-feature extraction and ensemble voting methods,”
Knowledge Based Systems 305, 112694,
https://doi.org/10.1016/j.knosys.2024.112694
Andrea R. Aikin is a freelance science writer and editor based in the Denver area. You can contact her at pivoaiki@sprynet.com.