KEY CONCEPTS
•
Artificial intelligence (AI) relies on data—lots of it—archived in a standardized, well-documented format.
•
Choosing an AI approach and interpreting the output require a thorough understanding of the type of problem and the capabilities of the method.
•
Statistical methods, physics-based modeling, digital twins and other tools can supplement machine learning models to strengthen predictions.
Tribology researchers begin using artificial intelligence (AI) for various reasons, depending on the type of problem they are trying to solve. For some, AI provides a way to supplement sparse experimental data. For others, AI offers capabilities to deal efficiently with an abundance of data. For others still, AI serves as a kind of virtual staff member, extending the capabilities of small research groups and finding trends and correlations in the data that are hard to detect otherwise.
Points of entry
STLE member Nikolay (Nick) Garabedian, Alexander von Humboldt postdoctoral Fellow at the Karlsruhe Institute of Technology in Germany, began looking into machine learning toward the end of his doctoral studies. He wanted to know if it was possible to use a single model to predict tribological behavior, given a wide set of variables. “Imagine a single equation that would predict friction at any scale, for any material pair, at any velocity, dry or lubricated,” he says. Even though machine learning models (algorithms that often power AI) seemed like the most promising way to address this challenge, these methods had not penetrated tribology research to the same extent as other scientific arenas, such as biochemistry and climatology, which only reinforced his curiosity.
STLE member Prathima Nalam, assistant professor in the Department of Materials Design and Innovation at The University at Buffalo, describes herself as an experimentalist and a relative newcomer to AI. Her research group tackles tribology problems using a variety of statistical tools in conjunction with AI to assist in making accurate predictions. The statistical methods are necessary, she says, because much of the wealth of tribology laboratory data collected over the past decades has not been archived in a centralized database form that is amenable to use in AI applications. Thus, she says, from an AI standpoint, tribology is a “data-sparse” field.
Dr. Adrian Hood, research mechanical engineer at the DEVCOM Army Research Laboratory, Weapons and Materials Research Directorate, in Aberdeen Proving Ground, Md., uses AI methods to extend the capabilities of his research group and discover patterns and trends in laboratory data. He and his colleagues work on damage detection in helicopter transmissions using a technique called seeded fault experiments. This technique involves deliberately introducing, or seeding, a specific type of fault into an otherwise undamaged part, to understand how the part behaves under various real-world test conditions.
In 2015, as free, open-source software for machine learning and AI became readily available to the community, Hood began to take an interest in AI studies. AI was already in use for processing acoustic signals for voice recognition when he began using it, so adapting these AI methods to the acoustic and vibration signals from moving mechanical parts was a natural next step.
Hood also couples his modeling work with these AI studies. The modeling helps him simulate more data, under more conditions, than is feasible from experimental work alone. The AI studies help him to understand and gain insights from the data by relating vibrational signals to physical principles. He notes that AI techniques are best suited to nonlinear problems that do not lend themselves to conventional statistical methods.
Rajiv Tiwari, professor of mechanical engineering at the Indian Institute of Technology Guwahati, has spent more than 30 years developing ways to monitor the health of various types of rotating machinery, with a special focus on gears and rolling element bearings. When he began this work in graduate school, he visually inspected vibration data signals and analyzed these signals in the time and frequency domains. Tiwari notes that in complex systems (a gearbox, for example), it is difficult to extract characteristic features from the noisy background. The situation becomes even more difficult in an industrial setting, when several such systems are present.
Tiwari began to look for ways to improve and automate the vibrational signal extraction process. One of his graduate supervisors expressed an interest in applying AI capabilities to analyzing vibration data from mechanical components at a power plant. This was during the early 1990s, when ready-to-use AI software did not exist, and AI pioneers wrote their own code in C language. Even after taking coursework in AI programming, Tiwari found that developing code for such a high-end application required a degree of expertise that exceeded his capabilities.
A decade later, when Tiwari was supervising students of his own, he and his research group were finally able to begin applying AI to diagnosing gear faults. They found innovative ways to ddress the challenges presented by gear systems, where continuously varying operating conditions often produce data unsuited for training conventional machine learning (ML) algorithms. They found that, even using limited data, an ML algorithm called a support vector machine worked with “reasonable accuracy”
(see Artificial Intelligence Terminology). They also succeeded in predicting gear failure in an industrial scenario, even if some of the sensors failed during the run. “We found that for any complex setup with proper planning on application of AI/ML, it works without bounds,” he says. He adds that AI/ML techniques have proven so useful over such a broad variety of applications that their perspectives on the types of problems they can address have broadened considerably.

Artificial intelligence terminology
Artificial intelligence (AI): A branch of computer science that focuses on algorithms and models capable of performing tasks that typically require human intelligence.
Artificial neural network: A type of machine learning in which layers of densely interconnected webs of processing nodes receive data from and transmit data to adjacent layers to produce the final processed output.
Convolutional neural network: A type of neural network that specializes in processing data that are easily represented as a grid (e.g., pixels in an image). Simple patterns are processed first, and successive layers of the network process increasingly detailed features.
Data label: The effect associated with a specific cause, or “example” (e.g., the change in viscosity associated with a specific oil formulation and temperature change).
Deep learning: The type of machine learning associated with neural networks containing more than three processing layers (including the input and output layer).
Digital twins: Virtual replicas of physical phenomena, systems or processes that are used to run simulations.
Hyperparameter: A configuration variable that is external to a model (e.g., the number of layers in a neural network). The value of the hyperparameter cannot be estimated from data.
Key-value pairs: Sets of data descriptors and data values associated with those descriptors (e.g., Name: John Smith).
Machine learning (ML): A type of AI consisting of algorithms that use input data to train a model to predict outcomes more accurately without being explicitly programmed to do so. ML is commonly used to drive and support other forms of AI.
Ontology: A set of concepts and categories that embodies information on a system’s properties and relations between these properties.
Parameter: A configuration variable, used for defining some characteristic of a model object, that is internal to a model. The value of the parameter can be estimated from the data, and its value generally remains the same over any given run of a simulation.
Physics-based learning: A modeling approach that integrates known physical laws and phenomena with numerical calculations to constrain the results of a numerical simulation within the boundaries of a defined space of physically reasonable results.
Supervised ML: An approach that uses labeled input data to train a model. The training set couples known causes and effects. The model then examines similar input not used in the training set to predict the corresponding effects.
Support vector machine: A type of supervised ML algorithm used mainly for classifying data into groups, based on plotting data points in n-dimensional space (where n is the number of features) and finding the hyper-plane that best separates various classes of data points.
Transfer learning: A type of ML that applies knowledge gained while solving one problem to solving a different, but related, problem.
Unsupervised ML: An approach that uses unlabeled input data to detect patterns and trends. Data can be sorted into clusters having some property in common, or correlations can be found between clusters of data having certain properties. The resulting clusters can be used as input to other ML algorithms.
Variable: A type of data, describing some characteristic of an object, that changes over the course of a model simulation.
RESOURCES:
50 AI terms every beginner should know: Click
here.
Machine Learning Glossary: Click
here.

Data demands
Machine learning algorithms help users to deal with data sets that are large (with respect to the number of runs and observations) and high-dimensional (with respect to the number of attributes and features), as well as managing information and generating new knowledge. Not surprisingly, the accuracy and utility of an AI/ML model rely, to a large extent, on the amount and quality of the data that go into training, validating and testing the model.
Nalam notes that there are existing material databases for known and predicted materials, including for metals and the small organic molecules used as lubricants and coatings. However, she says, these databases are not set up to work specifically on tribology problems, and at present, there is no centralized database of AI-ready, tribology-specific data. However, she adds, “There is this whole set of statistical tools that you can use, especially and exclusively for data-sparse fields to make accurate predictions”
(see Tackling 2D Lubricant Additives).
Tackling 2D lubricant additives
In Nalam’s research on the thermodynamics of 2D materials for use as lubricant additives, it’s not uncommon to use high-throughput computational approaches to generate sets containing thousands of hypothetical candidate materials that have not been synthesized yet. Synthesizing and running experiments on all of these materials to determine which ones reduce friction most effectively is not practical.
“I only had experimental and density functional theory (DFT) friction data on five or six materials. But I had a whole descriptor set of 15 parameters that can influence friction,” she says. She notes that some 2D material databases contain 30-50 descriptors, but her group examined the data to see which parameters had the most impact on friction. They applied these parameters to 10 2D materials that had not been previously characterized with respect to their tribological properties to calculate how these parameters affected friction.A “So even though we are in a data-sparse area, there are methods and approaches that allow us to move ahead, to make these predictions.”
REFERENCE
A.
Baboukani, B.S., Ye, Z., Reyes, K.G. and Nalam, P.C. (2020), “Prediction of nanoscale friction for two-dimensional materials using a machine learning approach,”
Tribology Letters, 68, Article 57. Available
here.
One way of generating input data is to gather and curate information from publications, materials databases and other sources to create a custom-made database—a potentially powerful, but extremely labor-intensive approach. Another way, automated laboratory testing, is an emerging approach to high-throughput data generation. Automated testing is especially useful for generating the large amounts of data needed for AI approaches to multiparameter problems (e.g., wear or fracture) because it can implement multiple tests with a large number of materials or a large number of parameters in a reasonable amount of time. Nalam notes that many industry labs have invested in automated testing facilities, and they have generated proprietary databases with sufficient information to be useful for AI studies. One way for academic laboratories to access this information, she says, could involve industry partnerships with companies that have automated laboratories capable of generating sufficient data.
Even in the absence of an abundance of data, however, there are ways to extract useful knowledge, Nalam says. For tribology in particular, the wealth of available empirical, thermodynamic and other computational models helps to compensate for the sparsity of accessible experimental data. She notes, for example, that physics-based learning can enable researchers to make much stronger predictions. Physics-informed ML, a relatively new approach, integrates ML models with mechanistic (physics) models while using available data to train the model in a synergistic manner. This approach can resolve complex processes and address application-centric objectives rather than relying entirely on the ML algorithms to identify patterns and trends. Incorporating physics-based knowledge of material properties and relationships also enables physics-informed ML to extrapolate beyond the existing data.
Supervised and unsupervised learning
Once the input data have been generated, curated and put into machine-readable form, they can be used to construct models and make predictions. Supervised and unsupervised learning are two approaches for applying AI to complex problems. The typical supervised learning approach requires large training sets consisting of labeled laboratory data from experiments or computational methods. The training sets test the impact of selected parameters, in isolation or in combination, on specific output. The ML algorithm then applies these parameters to similar data not included in the training set to make predictions.
Selecting a “good” problem to work on using this approach involves assessing the availability of enough data to generate meaningful statistical results. A problem that might be interesting or especially useful, like identifying causes of pitting or fretting in a gear system, might lack sufficient input data to form reasonable predictions because it is a simultaneous multi-parameter estimation problem, Nalam says. The performance of a particular gear system, for example, relies on multiple properties of the lubricating oil, the gear materials and the operating conditions, among other factors.
In tribological studies, any particular phenomenon is likely to be influenced by multiple parameters, some of which come into play at different times, Nalam says. Examining all of the interacting parameters experimentally is often not feasible. Thus, a conventional laboratory study will examine two or three parameters (e.g., temperature and pressure). However, unsupervised learning helps in considering a much broader set of interacting parameters. In unsupervised learning, all of the available information is used as unlabeled input for the calculations, and the AI algorithm finds hidden patterns and trends in data with minimal to no human intervention. This approach works best with large volumes of data because the algorithm must learn to categorize the input data without the benefit of training datasets.
One type of unsupervised learning involves looking at the descriptors—also called attributes or features—that might affect a particular material property (e.g., hardness), along with all the associated properties that might affect the material’s behavior. The AI algorithm identifies the factors that are most likely to affect specific material properties. Focusing on these factors makes it possible to reduce the dimensionality of the problem (i.e., the number of descriptors needed in the calculations), which simplifies the analysis.
Unsupervised AI adds even more utility to fault detection and diagnosis because the user is not required to anticipate and test all the possible relationships in the data, Hood says. Rather, an unsupervised AI algorithm like a convolutional neural network-based autoencoder discovers the subtle patterns and trends in a large input data set. The algorithm then transforms the data into a set of relevant data-driven features—a reduced representation of condition indicators. These features can be used for building models (using supervised ML algorithms or other methods) to make predictions of specific responses of interest. “Not everything in the AI is automated, though,” Hood explains. “We still have to determine the hyperparameters, such as how many layers, how many filters and what filter types and sizes to include in the neural network.”
Because unsupervised processes allow the algorithm to find patterns on its own, the output can resemble a “black box,” with little indication of how the machine arrived at its results or how to interpret the results in terms of physical processes. Hood notes that many researchers use a hybrid approach like physics-informed ML to create a “partial black box” model. Ideally, this approach not only identifies solutions that work well but also gives some indication of why they work well. However, this type of effort is still a work in progress, he says.
Making data usable
Many algorithms provide outstanding performance for different well-defined tasks, Garabedian says. For example, classical AI methods (those not based on artificial neural networks) can harness researchers’ domain knowledge and excel at performing tasks that would otherwise take a prohibitively long time. When the necessary knowledge is missing, models based on artificial neural networks can help. The output from these models is harder to explain in terms of physical laws and phenomena, but they can at least serve as the initial direction for investigators to focus their efforts, he explains.
All these computer methods, however, expect that the data they work with is in a perfectly structured format with an unambiguous meaning, Garabedian says. He explains that the way this is often done now is to collect a dataset and then construct a corresponding specific ML model in a case-by-case fashion. “If I wanted to find the answer to my initial question—
Is there a single tribology equation?—I had to find a way to tackle the problem of quality data collection at scale,” he says. He describes an ideal “big data” approach that would use separate sets of agents: one set focused on enlarging a dataset and the other set focused on analyzing the data.
The data sparsity that plagues AI approaches to tribology problems is due, in a large part, to lack of accessibility rather than an actual lack of data, Nalam says. She explains that tribologists have spent many decades amassing experimental data on specific mechanical components and systems under specific conditions. Organizations like ASTM and NLGI have published standard material classifications and detailed procedures for standardized testing, resulting in a wealth of data gathered according to well-specified procedures. In-house and customized testing and evaluation for materials and conditions not covered by the standard procedures have produced another large body of data, she says.
Data from all these tests are contained in individual journal publications and conference presentations, proprietary databases and researchers’ computer files and laboratory notebooks. Efforts are underway to assemble these data into tribological databases for use in data science applications, but these efforts are still in the discussion phase, Nalam says. She notes that the process is complicated by the number of stakeholders involved. For example, many companies have extensive data archives, but they might be reluctant to grant access to this valuable information. Publications in the scientific literature tend to focus on successful experiments, she adds, even though failed experiments can be just as useful (or sometimes even more so) for making predictions.
Another challenge is compiling data from various laboratories, instruments and published sources into a standard format that allows for standard calculations and meaningful comparisons. Other fields, including astronomy and bioinformatics, have pioneered methods and standards for building databases that are standardized, accessible and amenable to preserving older data while evolving to stay current with new instrumentation and analysis techniques. Thus, Nalam notes, tribologists do not have to start from scratch, but can use lessons learned from these more established efforts as a guide to building their own databases.
Perhaps one of the most difficult aspects of compiling a database for use with AI is ensuring that all the entries include metadata on data provenance, experimental conditions and quantified error and uncertainty information. Getting a diverse body of stakeholders to come to consensus on what these standards should be is a big part of this challenge, Nalam says. As researchers gain experience in providing data in a widely accepted standard format—and as journals and grant-making organizations begin to require standardized data—this becomes easier. However, older data can still be useful, once they have been adapted and documented.
Tribological properties are system properties, Garabedian says, so standardizing tribological data becomes a challenge that goes beyond the prescription of terms and units that describe the sliding process. Instead, all processes and objects that have preceded the system’s current state have to be fully accounted for. In an experimental setting, this consists of all production steps that shape the raw materials into usable tribological specimens. The technical specifications of all machines that are involved in this process chain also must be described.
Data sets that contain all of this information are described as FAIR (findable, accessible, interoperable and reusable). To fulfill these standards in tribology, Garabedian says, will take a significant shift in the way that tribologists collect and share data
(see FAIR Data). At present, there usually isn’t enough information collected to make tribology data FAIR retroactively, Garabedian says. It takes some introspection to decide how many details must be accounted for in order to transform tribology data into its FAIR version, he adds.
FAIR data
Humans are adept at processing messy data. For example, if you have some basic cooking experience, you can use cursive handwriting on an index card, a printed page in a book or on a website or a photograph of a pile of groceries on a countertop as instructions for making a pot of chili.
Computers need more assistance in figuring out what goes where, especially when they are processing massive amounts of data representing complex, interacting systems. Not only must data be available in a standardized format, they also must contain information on where, how and when they were obtained. Datasets must be easy to find and access, and they must be amenable to use by a broad variety of modeling and analysis programs, even as these programs evolve and change over time.
FAIR data principles are designed to guide researchers in producing data that are findable, accessible, interoperable and reusable.
Findable: Data are described using rich metadata, and both data and metadata are assigned globally unique and persistent identifiers. Metadata clearly and explicitly include the identifiers of the data they describe, and both data and metadata are registered and indexed in a searchable resource.
Accessible: Data and metadata can be retrieved by their identifiers using a standardized communications protocol. This protocol is open, free and universally implementable. Where necessary, the protocol allows for an authentication and authorization procedure. All metadata are accessible, even if the associated data are no longer available.
Interoperable: Data and metadata use a formal, accessible, shared and applicable language to represent knowledge, and they include qualified references to other data and metadata.
Reusable: Data and metadata must be richly described with accurate and relevant attributes, including detailed information as to their provenance. They must be released with clear and accessible licenses for their usage, and they must meet domain-relevant community standards.
RESOURCES
FAIR Principles: Click
here.
Wilkinson, M., Dumontier, M., Aalbersberg, I., et al. (2016), “The FAIR guiding principles for scientific data management and stewardship,”
Sci Data, 3, 160018. Available
here.
Garabedian and his colleagues have begun “FAIRizing” their data collection
(see Figure 1). “With the standardized datasets that we hope to start producing in the short term, we expect that we will be able to perform ML at scale, once the system is deployed.” However, he adds, they currently have a prototype for only one pinon-disk tribological experiment, which they would like to share with the tribology community in the form of a publication before implementing it at a larger scale.
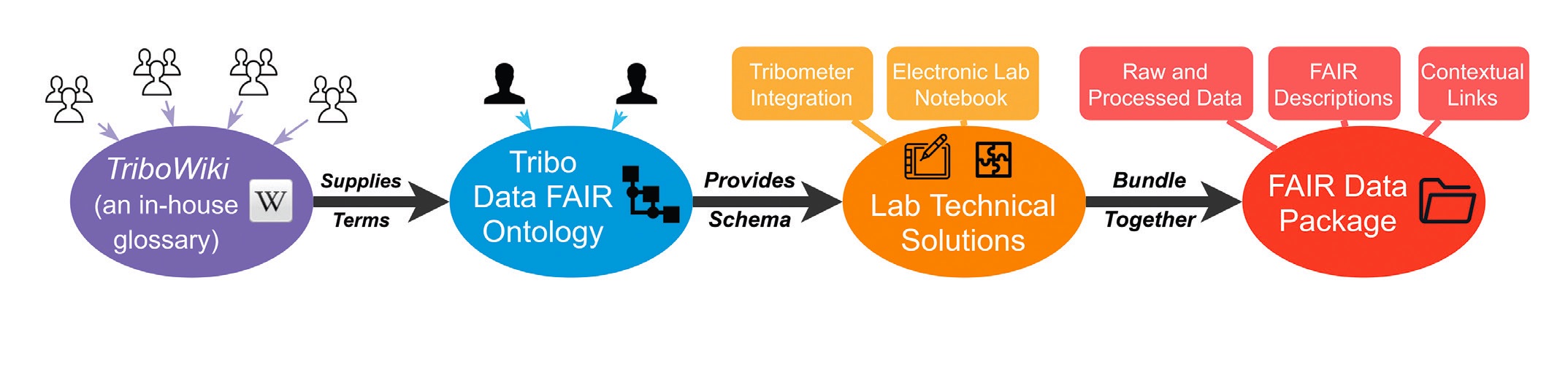 Figure 1. Process for generating a FAIR data package. Figure courtesy of Nikolay Garabedian and the materials tribology group at KIT IAM-CMS.
Figure 1. Process for generating a FAIR data package. Figure courtesy of Nikolay Garabedian and the materials tribology group at KIT IAM-CMS.
Coming up with that one prototype was no small task, Garabedian explains. Sixteen people were involved in the production effort. The ontology (the set of concepts and categories that embodies information on the properties and relations between these properties) consists of 4,902 logical axioms. The case-specific dataset consists of 1,857 key-value pairs that describe the process in a machine-readable form. “The experience of producing this one FAIR dataset showed us the scale of efforts necessary to digitize only one of the many experimental workflows.”
Applying AI effectively
“AI/ML techniques are effective when we want to automate a particular analysis and investigate a system that is complex and for which analytical modeling is difficult,” Tiwari says. Even the best physics-based models can produce erroneous output if the uncertainties in the input are large. However, including AI/ML approaches to study systems can produce usable output even with less-than-perfect input data. For example, AI/ML can produce “digital twins” (virtual replicas) of the experimental data, which can form the basis of more realistic predictions.
The limitation of AI/ML is that physical insight to the actual problem is often lacking, Tiwari says, adding that building better physics-based models is an ongoing challenge. Several industries are working on using AI/ML along with mature commercial or in-house finite element software to reduce the computational resources needed to generate physics-based models of mechanical systems. One approach is to train the AI/ML software in a modular fashion using parallel processing. This approach can speed up calculations, in contrast to the conventional sequential approach to finite element modeling.
AI is well suited to examining the variety of factors that can produce gear faults, Tiwari says
(see Figure 2). Industrial gear setups are especially useful for producing the large amounts of system performance data that are required to train AI/ML systems and construct data-driven models for predicting these faults. Such predictions include not only the type of fault but also the severity of the fault. The best part, Tiwari says, is that after doing some normalization, data from one system can be used with similar types of systems of different sizes. “Scaling to a bigger system or a large number of systems is relatively straightforward through AI/ML,” he says.
 Figure 2. Various levels of gear faults. Figure courtesy of Rajiv Tiwari.
Figure 2. Various levels of gear faults. Figure courtesy of Rajiv Tiwari.
Gear fault effects can be mechanical (vibrations and loss of efficiency), hydraulic (aeration, cavitation or leakage) or electrical (stray currents or corrosion). AI/ML techniques, including support vector machines and deep learning, can predict these faults quite accurately, Tiwari says. Predicting various types of faults and wear levels in bearing rolling elements also has been done successfully, he adds. For example, AI/ML was able to predict rolling element failure in an induction motor with a combination of vibration and electrical faults with a good confidence level.
1, 2
Tiwari explains that various AI/ML methods are very effective in understanding the behavior of a mechanical system, but the type of problem determines which method will be most effective in solving it. For example, a support vector machine is effective when fewer data sets are available to train the algorithm, but a significant amount of pre-processing of the data is required. In contrast, deep learning requires a large number of data sets, but raw data can be used as input.
Data pre-processing involves performing statistical operations on time domain data or transforming these data into a new domain—using wavelets (a mathematical tool for extracting information from audio signals), for example.
3 In contrast with simple analyses like binary classification of faults
(see Figure 3), transformed data are not easily interpreted using visual inspection
(see Figure 4). AI/ML, however, excels at this type of analysis, which is especially useful for multi-class fault prediction.
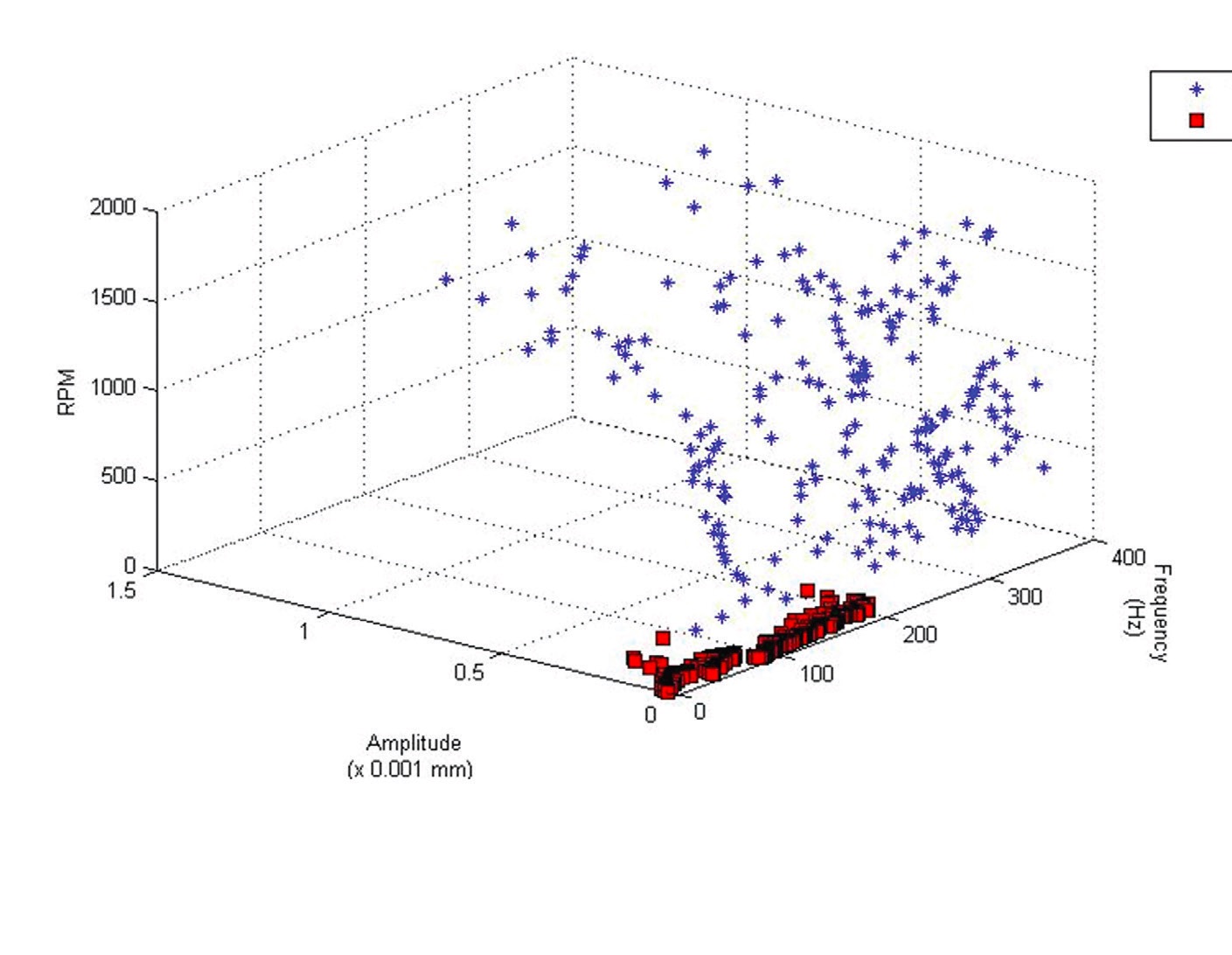 Figure 3. Spatial distribution of data sets for healthy gear versus worn gear. Figure courtesy of Rajiv Tiwari.
Figure 3. Spatial distribution of data sets for healthy gear versus worn gear. Figure courtesy of Rajiv Tiwari.
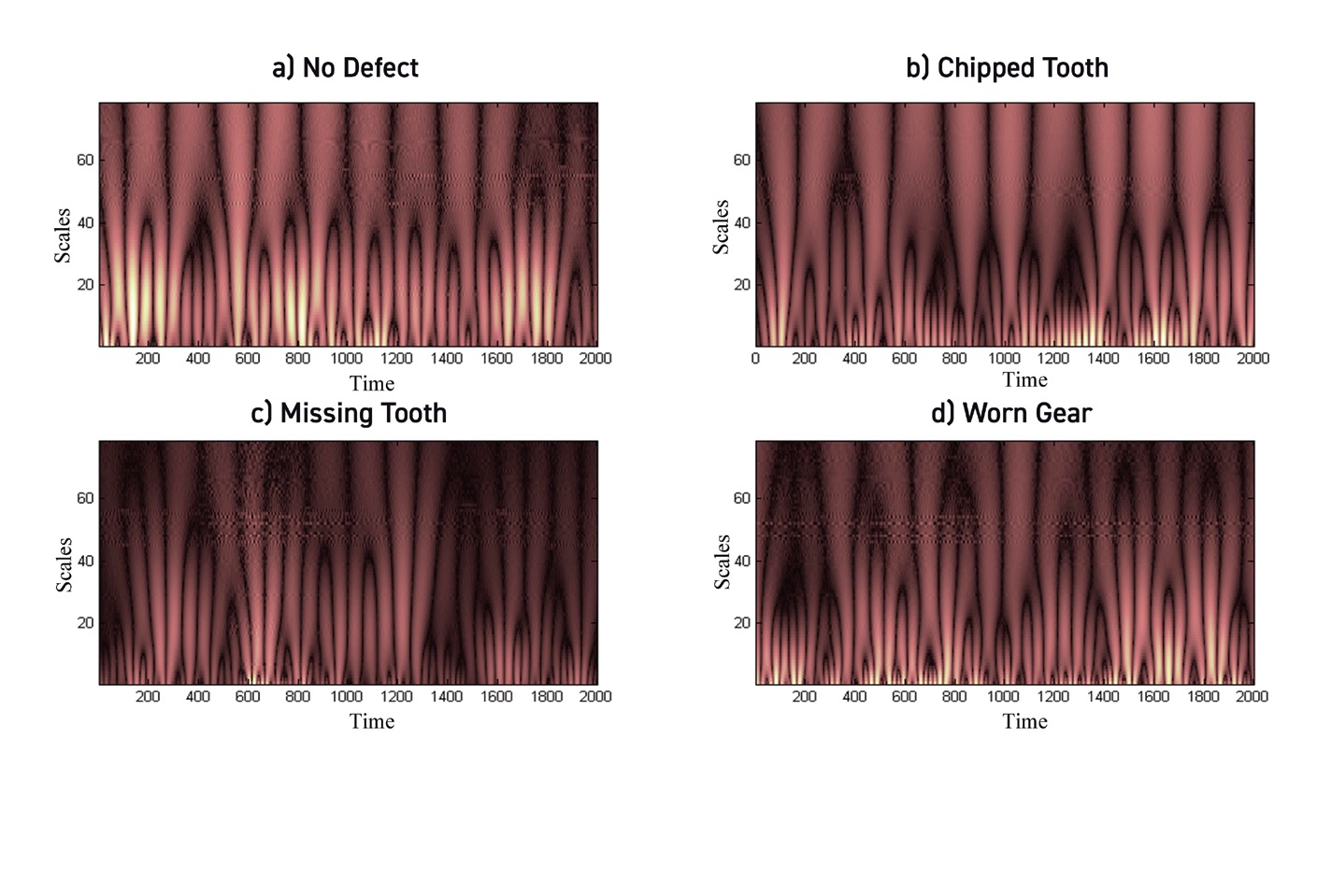
Figure 4. Plot of similarity coefficients for Mexican hat wavelet calculations (frequency versus time) for various type of defects in gears. Figure courtesy of Rajiv Tiwari.
Putting the data to use
AI is useful for “gap studies,” Hood says. “What holds us back from achieving a certain task?” For example, his group recently conducted a study on crack formation in the sun gear of a helicopter transmission. The sun gear—the central gear, around which the planet gears rotate—turns the helicopter rotor shaft. Sensors mounted on the gear housing have difficulty detecting signals from a crack in the sun gear because of the planet gears between the sun gear and the housing. Hood is using modeling to predict how big a crack in the sun gear would need to be to register a signal at a housing-mounted accelerometer sensor. He also is looking at what kinds of signals are produced as a function of crack size.
Eventually, he hopes to be able to predict not only the size of a flaw but to generate prognostics that could be used to recommend reducing power or torque levels to extend the life of a gear after a flaw is detected, until a replacement part can be installed.
4 “This is part of the overall goal to determine the state of the entire transmission, and eventually the state of the entire helicopter,” Hood says. In general, the goal is to determine which vehicles can support the mission and to determine, in real time, the state of each vehicle. “That helps us with our readiness and reduces maintenance time,” he says.
As it stands now, Hood sees the greatest need for improvement in developing high-quality input and the conditions used to construct models, rather than the abilities of AI itself. Gathering a sufficient amount of good input data—especially field data—on incipient faults and fault development is of particular concern. Fortunately for helicopter pilots and passengers, the types of faults that Hood’s group studies do not occur frequently in the field (although when they do occur, the consequences can be serious).
When a part does become damaged in the field, sensors may or may not be recording data as the damage occurs. Hood notes that the UH-60 helicopter has an integrated vibration health management system (IVHMS) to assist with condition-based maintenance. These sensors, however, are mainly used for damage detection and maintenance purposes, rather than for collecting laboratory-quality data. In contrast with laboratory data, taken over brief sampling intervals to produce a continuous detailed record, IVHMS systems take a brief sampling of data at intervals separated by several minutes. Also, some types of sensor systems do not save raw data. Rather, they perform calculations to produce condition indicators in order to save storage space on the on-board computers. Without the raw data to process, signals that the AI algorithm might have been able to use for pattern detection are not available.
Thus, baseline data from the field and lab characterize the undamaged system for a neural network. Seeded fault testing in the lab can help to fill in the extensive data needed to train an AI algorithm to detect and characterize faults.
5 Laboratory tests are especially useful for anomaly detection. Laboratory-produced anomalies produce a characteristic output signal, which the AI network can detect. Any available field data for flawed parts, along with modeling output, also can be used to supplement the laboratory data.
Hood’s group is currently working with the Rochester Institute of Technology to create a database of gear crack initiation and propagation research. This database includes a study in which a gear was subjected to a cyclic load until a hairline crack developed in one of the gear teeth. Sensors detected the crack growth while the gear was still inside the gearbox, and they collected vibration signals at the same time. The group is currently working on using ML techniques to correlate the vibration signals with the size of the developing crack in order to predict when the gear tooth will fail. They are still developing this modeling capability, but they plan to release an open-source repository of their data. Hood notes that the documentation phase, which is currently in progress, is critical to making the data useful for other researchers. “When a person downloads the data, they understand how the research was done, how to process the data and the code that was used to process it.”
Hood’s group also recently completed an exploratory research project to estimate the age of the grease in a helicopter bearing. To construct a training set for their model, they collected acoustic emission and vibration signals during an accelerated aging laboratory test at one-second intervals 24 hours a day over 860 hours of running time. They found that they could input a one-second snippet of this data (called an “instance”) to a multi-sensor feature fusion convolutional neural network, which could determine the age of the grease to within 10 hours (99% confidence). They are currently setting up a second run, extending to failure, to use in validating their results.
Garabedian has used ML to get a handle on an otherwise unwieldy laboratory dataset. He used ML to assist him in analyzing a large volume of existing, but largely unexplored, X-ray diffraction (XRD) data for tribologically stressed copper samples. The data had all the components that made it suitable for ML analysis, he says. The dataset was large (13,000 diffractograms), and it had a tangible, set number of dimensions.
Garabedian trained an algorithm to segment the XRD data into diffraction patterns from fine and coarse copper grains. Humans can perform this task relatively easily, he says, but there isn’t a closed-form (analytical) method based on theoretical principles that a computer could apply. However, ML could train an algorithm to separate the two types of patterns, he says. He describes this approach as a form of supervised learning, in which he manually labeled a subset of diffractograms (128 out of 9,891), and then let the model label the rest. The manual annotation took about six hours. However, given the prospect of having to spend about 77 times longer to annotate all the images, this made the difference between implementing the segmentation on the entire dataset and not doing so.
Garabedian and his colleagues have used an artificial neural network to confirm the systematic relation between the XRD data and tribological data. They are currently collaborating with a team from São Paulo University to find the underlying relations between accumulations of plastic deformations in copper and the friction force that it takes to produce them. “Once you are equipped with ML skills and viewpoint, you start seeing the many opportunities there are for its use,” he says.
AI opens up new capabilities
Nalam notes that AI has enabled her to study complex problems, not all of which can be tackled by simply running more experiments. The common experimental approach of varying one factor at a time, while holding the others constant, does not always produce results that resemble real-world situations, she says. AI has allowed her to examine complex problems involving multiple interacting phenomena, which has allowed her to tackle property prediction problems and parameter problems, even with sparse data. She stresses the need for collaboration across various fields (e.g., materials science and statistics) to ensure that the models and predictions are meaningful.
ML is a fairly new technique in the tribology field now, but there is a large body of relevant published data on lubricant formulations and corrosion-resistant steels, to name just two areas. As the field moves forward, predictions from a materials aspect will become more useful for things like gear and engine designs, Nalam says. Researchers will be able to work on more complex problems and predictions, like understanding the origins of wear. Electric vehicle motors are one area that is ripe for development, she adds. Corrosion and oxidation resistance, lubricant viscosity and other aspects of electric motors are significantly different from internal combustion engines, and the push from governments and industry to adopt electric vehicles means that manufacturers and suppliers will have to come up to speed very quickly.
Vibration, current and pressure data from test setups have proven useful in fault detection and diagnostics, Tiwari says. He cites the examples of predicting physical blockage in the inlet or outlet pipes of centrifugal pumps,
6, 7 pump cavitation and combinations of faults in an induction motor (e.g., hydraulic and mechanical faults or mechanical and electrical faults). “We found that often we achieved 100% success,” he says. In fact, finding the limits of prediction capabilities of the AI/ML techniques required unusual performance checks, he says—testing their fault prediction algorithms with limited or missing data or even faults in the sensor from which they captured the data. But even here, AI/ML gave promising results, he says.
“AL/ML can be applied to any new idea that we get from brainstorming or from the constraints of a practical scenario,” Tiwari says. For example, if it proves impractical to mount sensors directly on a pump submerged in a working fluid, the pump’s health can be monitored based on the current signal from its prime mover, which is mounted far away from the pump. Tiwari’s group also successfully detected a fault in a bearing—along with its location and severity—using current supplied to an associated induction motor. Tiwari notes that this type of monitoring would not have been possible using conventional physics-based models. He adds that AI/ML has successfully extrapolated from existing data to predict mechanical behavior for operating conditions not described by the available data.
The best part of AI/ML is that it is equally effective for conducting novel research and for direct implementation to solve industrial problems, Tiwari says. At present, most industrial problems are solved using conventional finite element analysis or finite volume-based commercial or in-house software. Industry relies heavily on these conventional methods, but the large amount of computation time required imposes constraints. Now, he says, industry is looking to integrate AI/ML with conventional methods
(see Figure 5). This approach balances physics-based and data-driven techniques, as well as reducing computational time.
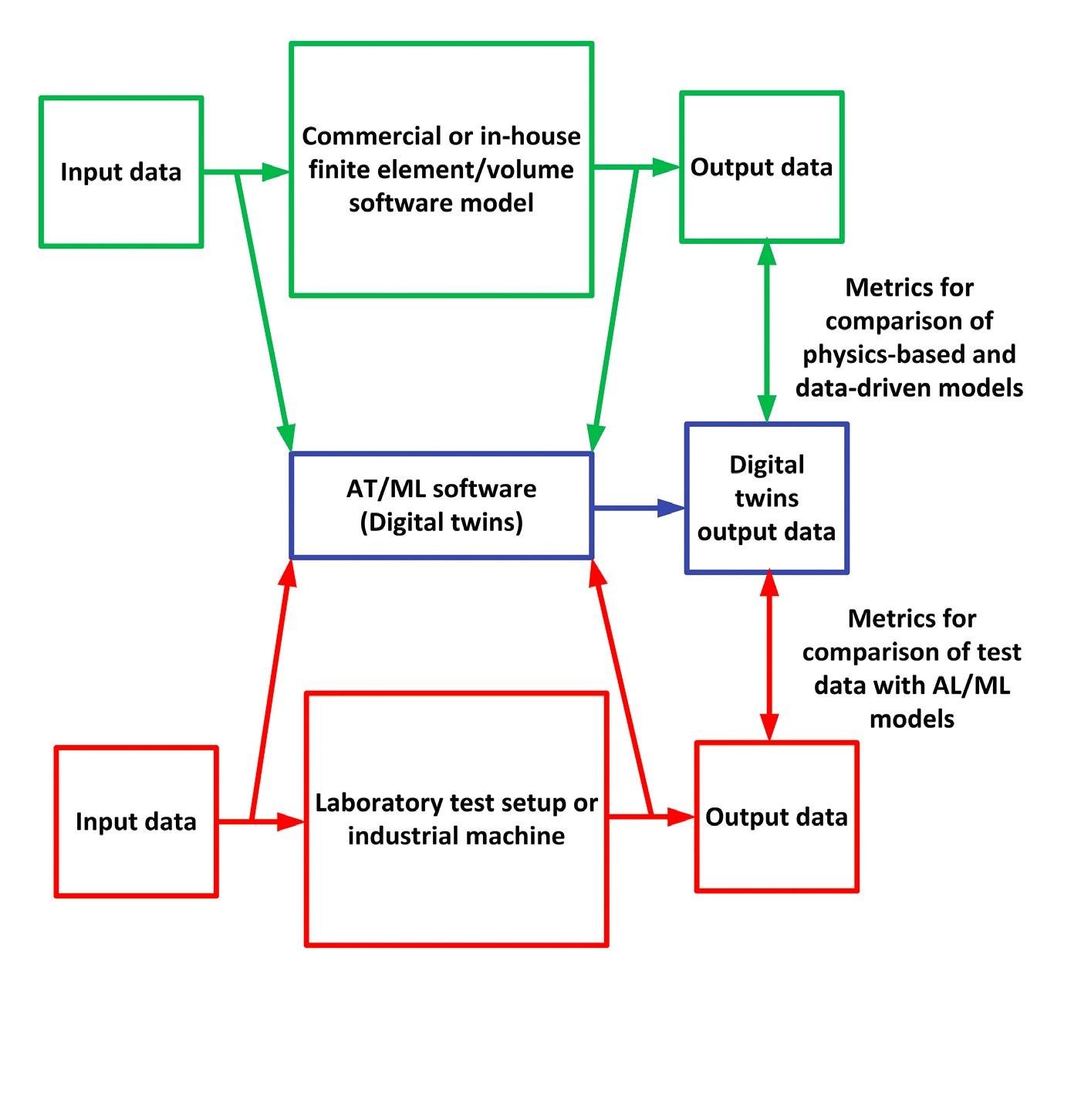 Figure 5. Future models may benefit from “digital twins” that integrate data derived from physics-based numerical models and experimental tests. Figure courtesy of Rajiv Tiwari.
Figure 5. Future models may benefit from “digital twins” that integrate data derived from physics-based numerical models and experimental tests. Figure courtesy of Rajiv Tiwari.
One emerging area in AL/ML, transfer learning algorithms, can mimic the analytical and data-interpretation skills of a human being, Tiwari says
(see Figure 6). For example, he says, a human learns some basic skills in a particular scenario and systematically applies the skills to different situations. In a similar fashion, transfer learning applies knowledge gained while solving one problem to solving a different, but related, problem. Tiwari sees a broad scope of potential applications of this capability in all fields tribology and allied areas involving mechanical components.
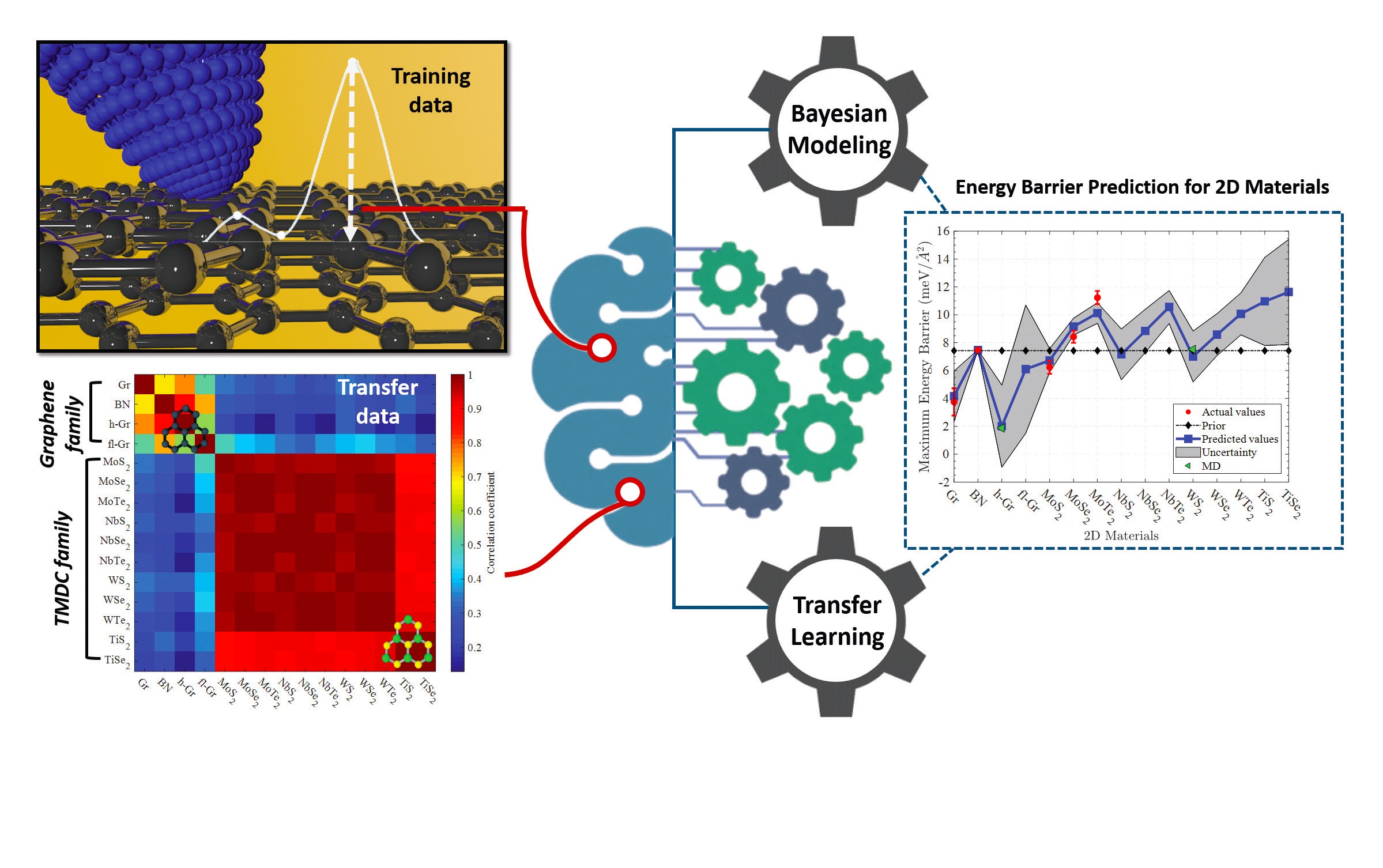 Figure 6. Transfer learning algorithms can mimic the analytical and data-interpretation skills of a human being. Figure source: Baboukani, B.S., Ye, Z., Reyes, K.G. and Nalam, P.C. (2020), “Prediction of nanoscale friction for two-dimensional materials using a machine learning approach,” Tribology Letters, 68, Article 57. Available here.
Figure 6. Transfer learning algorithms can mimic the analytical and data-interpretation skills of a human being. Figure source: Baboukani, B.S., Ye, Z., Reyes, K.G. and Nalam, P.C. (2020), “Prediction of nanoscale friction for two-dimensional materials using a machine learning approach,” Tribology Letters, 68, Article 57. Available here.
It is inevitable that we are going to see ML employed as a tool for data analysis on project-by-project basis, Garabedian predicts. “However, in my opinion, the most significant developments in the short-to-medium term will come in the form of uniting the academic and industrial sectors into consortia for exchanging FAIR tribological data. This is the only viable way for assembling a digital knowledge base that will accelerate our ability to innovate and also prevent us from investing time into re-running old experiments that somebody else has probably already performed.” He cites the FAIRsharing website (
http://fairsharing.org) as one such platform for sharing FAIR standards, databases and other information. His group recently submitted an ontology to FAIRsharing (
https://beta.fairsharing.org/3597) that provides a controlled vocabulary of terms used to describe the scientific procedures in an experimental tribology lab.
The road ahead
Tiwari sees numerous opportunities for researchers and practicing engineers to apply AI/ML methods to mechanical components. AI/ML methods excel at using data from experiments and numerical modeling to construct models of complicated phenomena, analyze system behavior and predict future behavior. In doing so, these methods have produced new findings as well as solving problems that were previously intractable because of the large amounts of information involved—and the limited number of experts available to analyze the data.
Nalam emphasizes the importance of collaboration between industry and academia. Academic research can benefit from industrial laboratory and automation resources, and industry can gain access to basic research and cutting-edge computational approaches. The dual focus on basic physics and practical applications will be critical to moving beyond a trial-and-error approach to addressing the types of complex problems that are typical of tribological research, she says.
Discovering new materials and predicting a material’s property in an accelerated and systematic manner is imperative for any technological advancement, including tribology, Nalam says. In the laboratory, advances in high-throughput experiments and combinatorial material processing techniques are catching up with computational approaches to generate data in an unprecedented way, she adds. If appropriate input data are available, she adds, ML-based modeling becomes a powerful tool to make accurate predictions.
REFERENCES
1.
Gangsar, P. and Tiwari, R. (2017), “Comparative investigation of vibration and current monitoring for prediction of mechanical and electrical faults in induction motor based on multiclass-support vector machine algorithms,”
Mechanical Systems and Signal Processing, 94, pp. 464-481. Available
here.
2.
Gangsar, P. and Tiwari, R. (2020), “Signal based condition monitoring techniques for fault detection and diagnosis of induction motors: A state-of-the-art review,”
Mechanical Systems and Signal Processing, 144, 106908. Available
here.
3.
Wang, W.J. and McFadden, P.D. (1996), “Application of wavelets to gearbox vibration signals for fault detection,”
Journal of Sound and Vibration, 192 (5), pp. 927-939. Available
here.
4.
Nenadic, N.G., Ardis, P.A., et al. (2015), Processing and interpretation of crack-propagation sensors, Annual Conference of the Prognostics and Health Management Society.
5.
Hood, A., Valant, C., et al. (2021), Autoencoder based anomaly detector for gear tooth bending fatigue cracks, Annual Conference of the Prognostics and Health Management Society.
6.
Kumar, D., Dewangan, A., Tiwari, R. and Bordoloi, D.J. (2021), “Identification of inlet pipe blockage level in centrifugal pump over a range of speeds by deep learning algorithm using multi-source data,”
Measurement, 110146. Available
here.
7.
Rapur, J.S. and Tiwari, R. (2018), “Automation of multi-fault diagnosing of centrifugal pumps using multi-class support vector machine with vibration and motor current signals in frequency domain,”
J. Braz. Soc. Mech. Sci. Eng., 40, 278. Available
here.
Nancy McGuire is a freelance writer based in Silver Spring, Md. You can contact her at nmcguire@wordchemist.com.